





Delta Lake
Defining and Describing Delta Lake
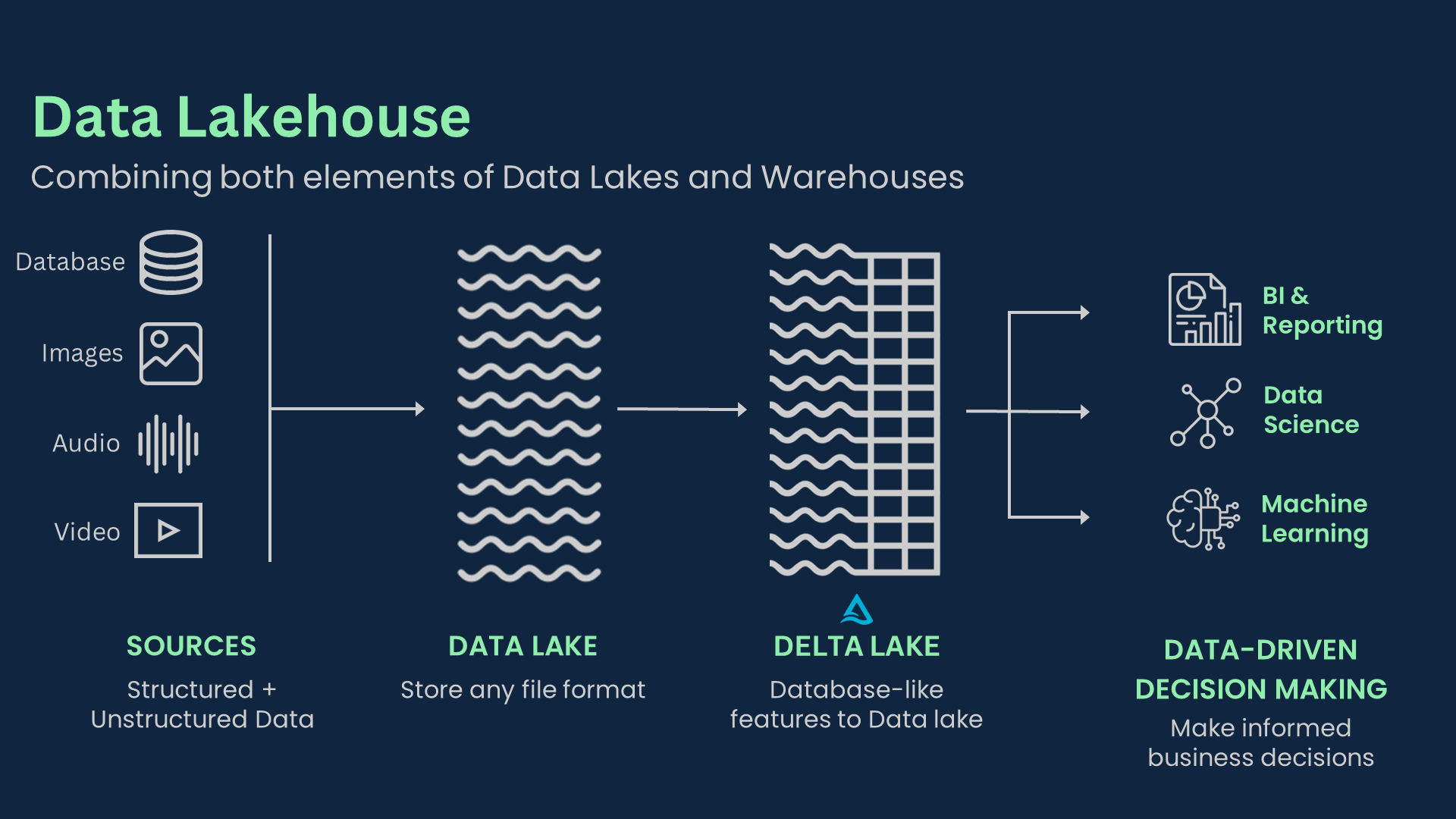
Delta Lake is an open‑source data table format and storage layer that sits on top of cloud object stores to turn a cheap “data swamp” into a reliable, governed analytics and AI substrate, especially in modern lakehouse architectures.[1][2][3]
Delta Lake applies when a team is working with a data lake on S3, ADLS, GCS, or similar and needs database‑like guarantees (ACID transactions, schema control, time travel) without giving up the scalability and low cost of raw object storage.[1][2][3] It does not replace your warehouse or your storage system; instead it overlays a transaction log and metadata model on Parquet files so multiple engines (e.g., Apache Spark, Databricks, others) can safely share the same tables.[1][2][3][5] An innovation consultant cares because adopting Delta Lake is often a foundational architecture choice that affects data quality, governance, cost structure, vendor lock‑in, and the feasibility of AI/ML initiatives in a startup or scaling organization.[2][3][6] It is central to the lakehouse pattern that many high‑growth companies are using to avoid traditional “warehouse vs. data lake” trade‑offs.[3][6][7]
Disambiguation
Primary sense — the innovation-consulting sense
Delta Lake (data table format / storage layer)A transactional storage layer and open table format that extends Parquet files on cloud object stores with a file‑based transaction log, giving data lakes ACID guarantees, scalable metadata, and unified batch/stream processing.[1][2][3]
- Delta Lake is an open‑source storage layer and table format that “sits on top of existing data lakes,” bringing atomicity, consistency, isolation and durability (ACID) transactions to workloads on S3, ADLS, and other object stores.[1][2][6]
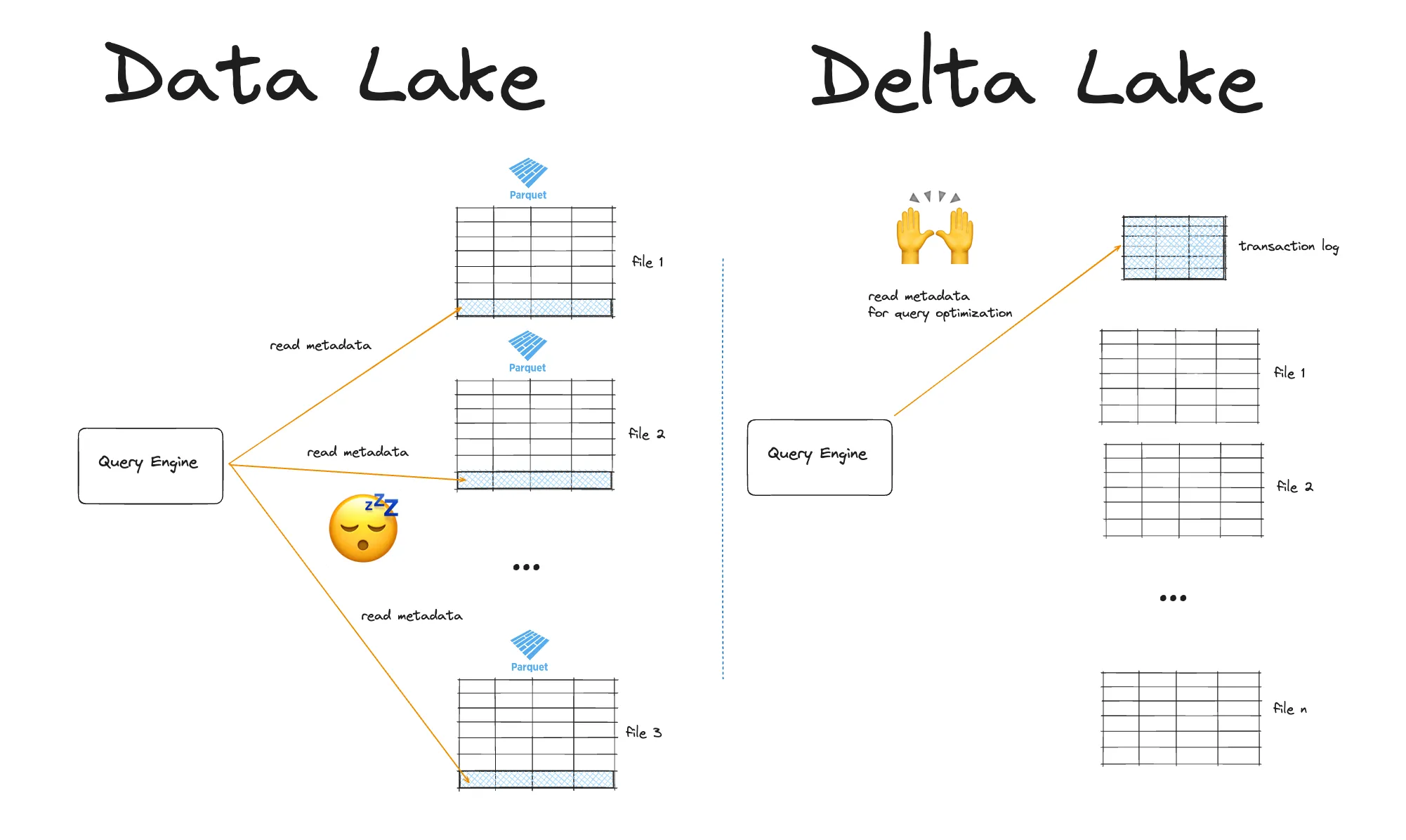
- Architecturally, it combines data files (typically Apache Parquet) with a transaction log (DeltaLog) that records every change to a table, providing versioned metadata and enabling features like time travel, concurrent writes, and efficient upserts.[2][3][7]
- It is tightly integrated with Apache Spark and Structured Streaming, allowing a single Delta table to act as both batch source and streaming source/sink so teams do not need separate infrastructures for real‑time and historical pipelines.[1][3][5]
- This sense is not a standalone database or storage system; Delta Lake relies on underlying object stores (e.g., AWS S3, Azure Data Lake Storage, GCS, on‑prem HDFS) and on compute engines (Spark, Databricks, etc.) to read/write Delta tables.[1][2][3][5]
Other senses
- Also used literally for geographical lakes in river deltas (e.g., environmental “delta lakes”); these physical bodies of water are not relevant to data, startup, or innovation contexts and are generally ignored in business/technology discussions of “Delta Lake.”
Etymology and Origin
- Delta Lake was developed by Databricks in 2016, originally as an internal technology to bring stronger reliability and governance to cloud data lakes before being open‑sourced.[2][3][7]
- Databricks “originally developed the Delta Lake protocol and continues to actively contribute to the open source project,” positioning it as the “optimized storage layer that provides the foundation for tables in a lakehouse on Databricks.”[3][4]
- The term migrated into broader innovation and data‑platform vocabulary as Databricks popularized the lakehouse concept, where “Delta Lake is the default format for all operations on Databricks” and thus became a de‑facto standard for many AI‑ and analytics‑driven startups.[3][4][7]
Adjacent Vocabulary
Synonyms (near-equivalents / same neighborhood)
- Open table format – General category for technologies like Delta Lake, Apache Iceberg, and Apache Hudi that define how tables are represented in data lakes; Delta Lake is one specific implementation with its own protocol and log format.[2][3][6]
- Lakehouse storage layer – Emphasizes Delta Lake’s role in the lakehouse architecture as the storage layer that unifies data lake flexibility with warehouse‑like reliability and performance.[3][6][7]
- Transactional data lake layer – Highlights the ACID and concurrency aspects: Delta Lake turns a basic data lake into a transactional system suitable for production workloads.[1][2][7]
- Delta table format – The practical synonym used by engineers: a “Delta table” is a table stored in the Delta Lake format on top of object storage.[3][5]
Antonyms (rough conceptual opposites)
- Raw data lake / data swamp – A simple file‑based data lake without transactional guarantees, often suffering from “data quality, consistency, and manageability” issues that Delta Lake explicitly aims to solve.[1][2][7]
- Tightly coupled monolithic data warehouse – A vertically integrated database/warehouse where storage and compute are locked into a single vendor system, the opposite of Delta Lake’s engine‑agnostic, object‑store‑based model.[2][6]
Adjacent terms (innovation-relevant neighbors)
- Data Lake – The underlying file‑based repository that Delta Lake upgrades with transactions and governance.[1][2]
- Lakehouse architecture – The hybrid model “where Delta Lake is the optimized storage layer that provides the foundation for tables in a lakehouse on Databricks.”[3][4][7]
- Apache Spark – The primary compute engine and API surface that Delta Lake was designed to integrate with, including Structured Streaming.[1][3][5]
- Apache Parquet – The columnar file format that stores the actual data files underneath Delta Lake’s transaction log.[2][3][5]
- Data governance – Area impacted by Delta Lake’s schema enforcement, versioning, and auditability.[1][2][6]
- ELT Tools – Data integration pattern that leverages Delta Lake for staging, transformations, and serving analytics/ML workloads.[2][5][7]
Usage in Practice
- Databricks’ own documentation frames it as infrastructure for production analytics: “Delta Lake transforms unreliable data lakes into production‑grade systems by adding ACID transactions, schema enforcement and time travel capabilities that enable you to reliably build and scale data pipelines and analytics on any cloud storage.”[7]
- Fivetran, as a data‑integration vendor, positions it at the governance layer: “Delta Lake is an open‑source storage layer — an open table format — that sits on top of existing data lakes… bringing atomicity, consistency, isolation, and durability (ACID) transactions to your workloads.”[2]
- A Baeldung engineering guide emphasizes its effect on architecture simplification: “Delta Lake simplifies data architecture by treating a table as both a batch source and a streaming source or sink. This unified approach eliminates the need for separate systems for historical and real-time data.”[1]
- A DataBricks overview for practitioners highlights its foundational role: “Delta Lake is open source software that extends Parquet data files with a file-based transaction log for ACID transactions and scalable metadata handling… [and] is the optimized storage layer that provides the foundation for tables in a lakehouse on Databricks.”[3][4]
- A Snowflake fundamentals article (written from a competitor’s perspective) still acknowledges the core concept: “Delta Lake is an open-source table format that brings structure and governance to data lakes. Instead of being just a dumping ground for files, a Delta Lake organizes data into tables with schema, metadata, and transactional guarantees.”[6]
- A GSPANN consulting blog, in the context of Azure Databricks, notes its multi‑cloud flexibility: “Delta Lake is an open-source storage framework that stores data and tables in Parquet files… The underlying storage layer for Databricks Delta Lake can be AWS S3, GCP GCS, or Azure BLOB.”[5]
Common Misuses
- Calling any object‑store table a “Delta Lake”Teams sometimes use “Delta Lake” to refer to any table stored in S3/ADLS; the precise term should be “Delta table” and only when the table is actually stored using the Delta Lake transaction log and protocol.[2][3]
- Equating Delta Lake with Databricks the platformMarketing and internal decks sometimes treat Delta Lake as synonymous with the Databricks SaaS product; the better term for the full commercial environment is “Databricks Lakehouse Platform”, with Delta Lake as its storage layer / table format.[3][4][5]
- Using “Delta Lake” to mean any lakehouseSome narratives use “Delta Lake” generically for any lakehouse‑style architecture, even when using Apache Iceberg or Hudi; the more accurate umbrella term is “open table format” or “lakehouse architecture,” with Delta Lake, Iceberg, and Hudi as distinct implementations.[2][3][6]
- Portraying Delta Lake as a standalone database replacementIn vendor or internal pitches, Delta Lake is occasionally described as if it were a full database/warehouse; the correct framing is “storage layer / table format on top of object storage” that still depends on engines like Apache Spark or SQL query services for compute.[1][2][3][5]
Sources
[1]: Introduction to Delta Lake | Baeldung
[2]: What is Delta Lake? Benefits, features, and architecture - Fivetran
[3]: What is Delta Lake in Databricks?
[4]: What is Delta Lake in Azure Databricks? - Microsoft Learn
[5]: Azure Databricks Delta Lake Best Practices - Gspann.com
[6]: What Is Delta Lake? A Guide to the Open Table Format - Snowflake
[7]: Delta Lake Explained: Boost Data Reliability in Cloud Storage