





software-development/databases/chromadb-backup
Table of Contents
Summary
2026-04-29 Call with Jeff Huberman
Financing History
Pre-Seed Round or Activity
| Amount | |
| Total | |
| Investor A | |
| Investor B | |
| Investor C | |
| Investor D | |
| Miscellaneous |
Seed
- Notable Individual Participants:
| $75M EV / Participants | Amount | EV |
| Total | $18M | 19.3% |
| Quiet Capital | ||
| Bloomberg Beta | ||
| Air Street Capital | ||
| AIX Ventures | ||
| Angels | ||
| Miscellaneous |
Round Details for this Round
Lead and Committed Participants
Terms-ish
"The Win" and Key Milestones Already Achieved (non-financial)
- Most Loved: most loved Vector database by open source and developer community
- Achieved meaningful internal Company Brains
"The Bet" & Key Expected Milestones (non-financial)
- market leadership on ingestion agents
Current Business
Defining Customer Account & Pipeline
Definition & Levels or Types with ASP & ARPC
Pipeline: Stages & Metrics
Conversion Hypothesis Discussions, role of OSS
Key Customers
- Paramount, Qualcomm
- Slack, Notion
Revenue trajectory vs Headcount
Plan to Ingest data Proactively
Competitive Set
Competitive Positioning
Financing & Valuation Comparison (as of April 2026)
| Company | Total Funding | Latest Round | Estimated Valuation | Key Investors |
| PineconeDB | ~$138M | $100M Series B/C (2023-2025) | $750M | a16z, Menlo Ventures, Index |
| Weaviate | ~$68M | $50M Series B (2026) | $200M+ | Index Ventures, Battery Ventures, NEA |
| ChromaDB | ~$18M | $18M Seed (2023) | $75M | Quiet Capital, Bloomberg Beta, Naval Ravikant |
| Pinecone (Serverless) | Weaviate (Self-Hosted) | ChromaDB (Distributed) | |
| Typical p50 Latency | 4–12 ms | 8–12 ms | 12–45 ms |
| Typical p95/p99 Latency | 12–45 ms | 65 ms | 70 ms+ |
| Queries Per Second (QPS) | Up to 50,000 | 10,000–15,000 | 5,000–8,000 |
| Scaling Mechanism | Native Auto-scaling | Sharding & Replication | Modular Distributed Core |
| Source: [7b69gi] |
Comparative Analysis: Traction & Approach
1. Pinecone: The Managed "No-Ops" Leader
- Traction: Widely considered the production-standard for enterprises that want to ship fast without managing infrastructure. It is optimized for high-performance, (sub-100ms).
- Enterprise Focus: Offers Multi Tenant Architecture, Serverless options, and robust security compliance. Its usage-based pricing can become expensive at massive scales, but it trades that cost for zero operational overhead. [9uqicx] [fhz60g] [4seog4] [znfkr0]
2. Weaviate: The Hybrid "Modular" Favorite
- Approach: Open-source core with a "hybrid deployment" model (Self-Hosted or Managed Cloud). [znfkr0]
- Traction: Favored by organizations with strict data residency requirements or complex data needs. It is highly modular, allowing developers to plug in different embedding models and vectorizers directly.
3. ChromaDB: The Developer-First Prototyper
- Traction: Dominates the prototyping and research stages. It is the easiest to set up (one-line install) and integrates natively with popular AI frameworks like LangChain and Hugging Face.
Summary of Positioning
- Pinecone is for Scalability & Ease (Buy speed and convenience).
- Weaviate is for Flexibility & Hybrid Search (Buy features and an off-ramp).
- Chroma is for Customization & Local Development (Buy simplicity and control). [owb9cd]
The Strategic Importance of Chroma in the AI Developer Community
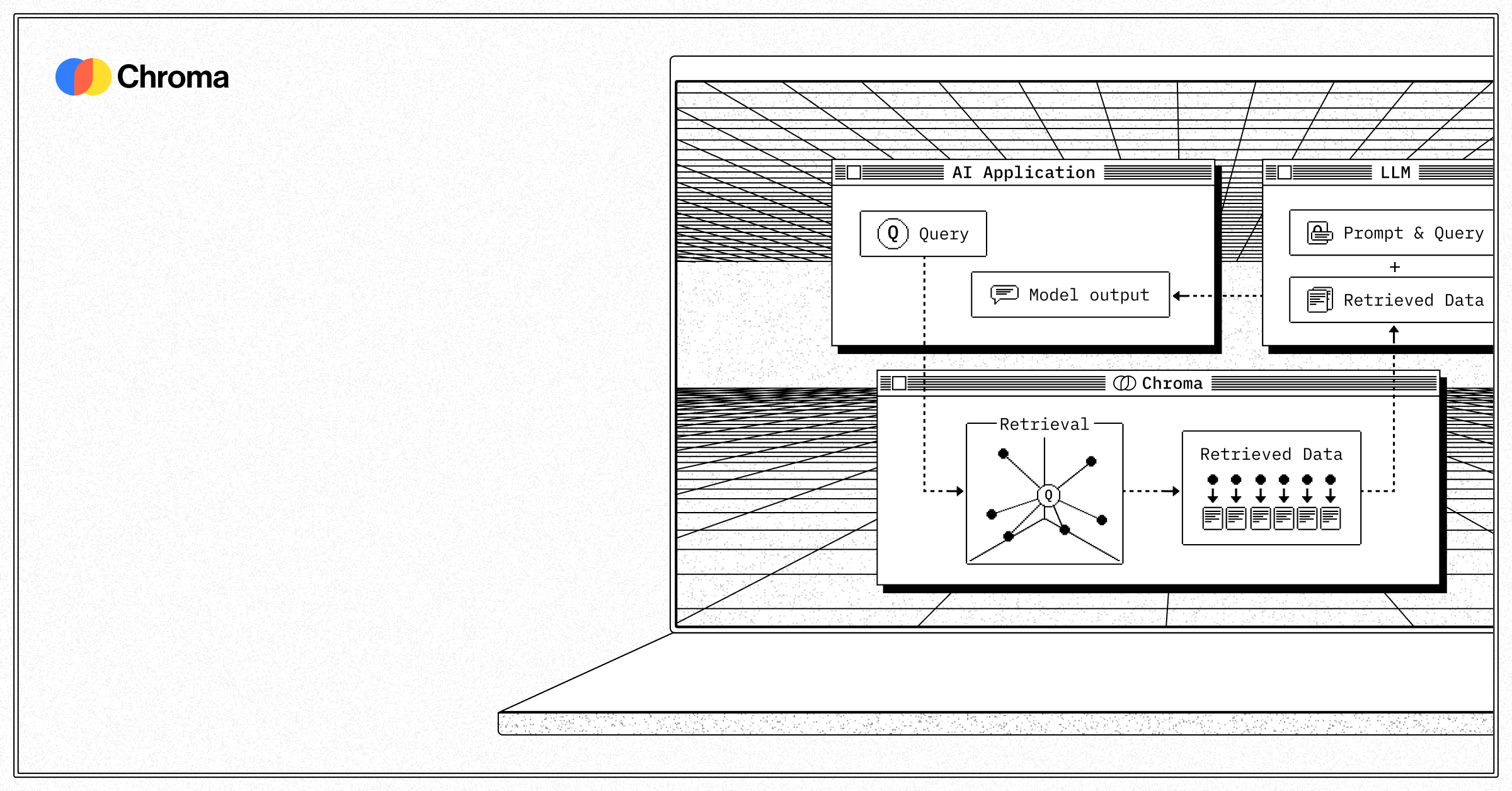
What is Chroma?
Why Chroma Matters to AI Developers
1. Developer-First Philosophy
- Minimal Setup: Developers can get started with just
pip install chromadband begin prototyping immediately [z2b0ci] - Simple API: Only 4 core functions (create collection, add, query, delete) make it incredibly accessible [n6pnxd]
2. Built for Modern AI Workflows
- Native Embedding Support: Automatically handles tokenization, embedding generation, and indexing [n6pnxd]
3. Recent Performance Revolution (2025)
- 4× faster for common write and query operations
- True multithreading without Python's GIL limitations
- 3-5× faster queries enabling large-scale sweeps in milliseconds
- Dramatically improved resource efficiency while maintaining API compatibility
Key Differentiators from Competition
Versus Pinecone
- Cost: Chroma is completely free and open-source, while Pinecone requires substantial investment ($200-$10K+/month for scale) [k01ei4]
- Control: Chroma provides complete infrastructure control; Pinecone is a black-box managed service
- Deployment: Chroma can run anywhere (local, cloud, embedded); Pinecone is cloud-only
- Learning Curve: Chroma's simplicity makes it ideal for prototyping; Pinecone requires understanding their specific architecture
Versus Weaviate
- Architecture: Chroma's single-node simplicity versus Weaviate's distributed complexity
- Setup: Zero configuration with Chroma versus Weaviate's schema requirements
- Resource Usage: Minimal footprint for Chroma; Weaviate requires higher baseline resources
- Use Case: Chroma excels at RAG and LLM applications; Weaviate targets broader enterprise search
Versus Qdrant and Milvus
- Developer Experience: Chroma's API is significantly simpler and more intuitive
- Integration: Native support for popular AI frameworks (LangChain, LlamaIndex)
- Iteration Speed: Faster prototyping and development cycles
Unique Capabilities for Developers
1. Seamless LLM Integration
# Simple RAG pipeline with LangChain
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
db = Chroma.from_documents(documents, OpenAIEmbeddings())
results = db.similarity_search(query)2. Flexible Storage Architecture
- Brute-force buffer for immediate writes
- Vector flush layer for optimization
- Disk persistence for durability
3. Advanced Query Capabilities
- Hybrid search: Combine vector similarity with metadata filtering
- Full-text search: Traditional keyword search alongside semantic search
- SpANN algorithms: Efficient filtered searches on large datasets
4. Production-Ready Features
- Horizontal scaling through Chroma Cloud
- Binary encoding optimizations for improved throughput
- Enhanced garbage collection for production deployments
What Chroma Enables That Others Struggle With
1. Rapid Prototyping to Production
- Start with a Jupyter notebook
- Scale to production without code changes
- Avoid the complexity cliff that plagues other solutions
2. Cost-Effective Scaling
- Handle millions of vectors on commodity hardware
- No per-query or per-vector pricing
- Community support reduces operational overhead
3. Framework Agnostic Development
- Works with any embedding model
- Supports multiple programming languages
- Flexible enough for custom implementations
4. Real-Time Experimentation
- Hot-swap embedding models during development
- Test different chunking strategies instantly
- Iterate on metadata schemas without migrations
Looking Forward
- Native bindings for JavaScript, Ruby, and Swift
- Seamless local-to-cloud workflows
- Enhanced enterprise features without complexity
Conclusion
Sources
[cplcj1] Vector database Chroma scored $18 million in seed funding at a $75 million valuation. Here's why its technology is key to helping generative AI startups. Business Insider
[01xra2] Vector Database Benchmark 2026 Salttechno
[07azvr] Architecture Overview Chroma Docs.
[4seog4] Vector Databases at Scale: Pinecone vs. Weaviate vs. Chroma in Production LinkedIn, Juaqin Marques. July 9, 2025.
Further Reading
[0q7uie] Vector Database Comparison: Pinecone vs Weaviate vs Qdrant vs FAISS vs Milvus vs Chroma (2025)
[fhz60g] 2025, Jul. "Pinecone vs Weaviate vs ChromaDB: Which Vector Database Should You Use for Scalable AI Search? | AGIX Technologies". AGIX Technologies. AGIX Technologies.
[qiq8py] 2023, Aug. "Weaviate Raises $50 Million Funding to Meet Demand for AI Vector Database Technology | AIMFG INSIGHTS". AIMFG Editorial Staff. AIMFG INSIGHTS.