





data-utilities/tiledb
Value Proposition & Features
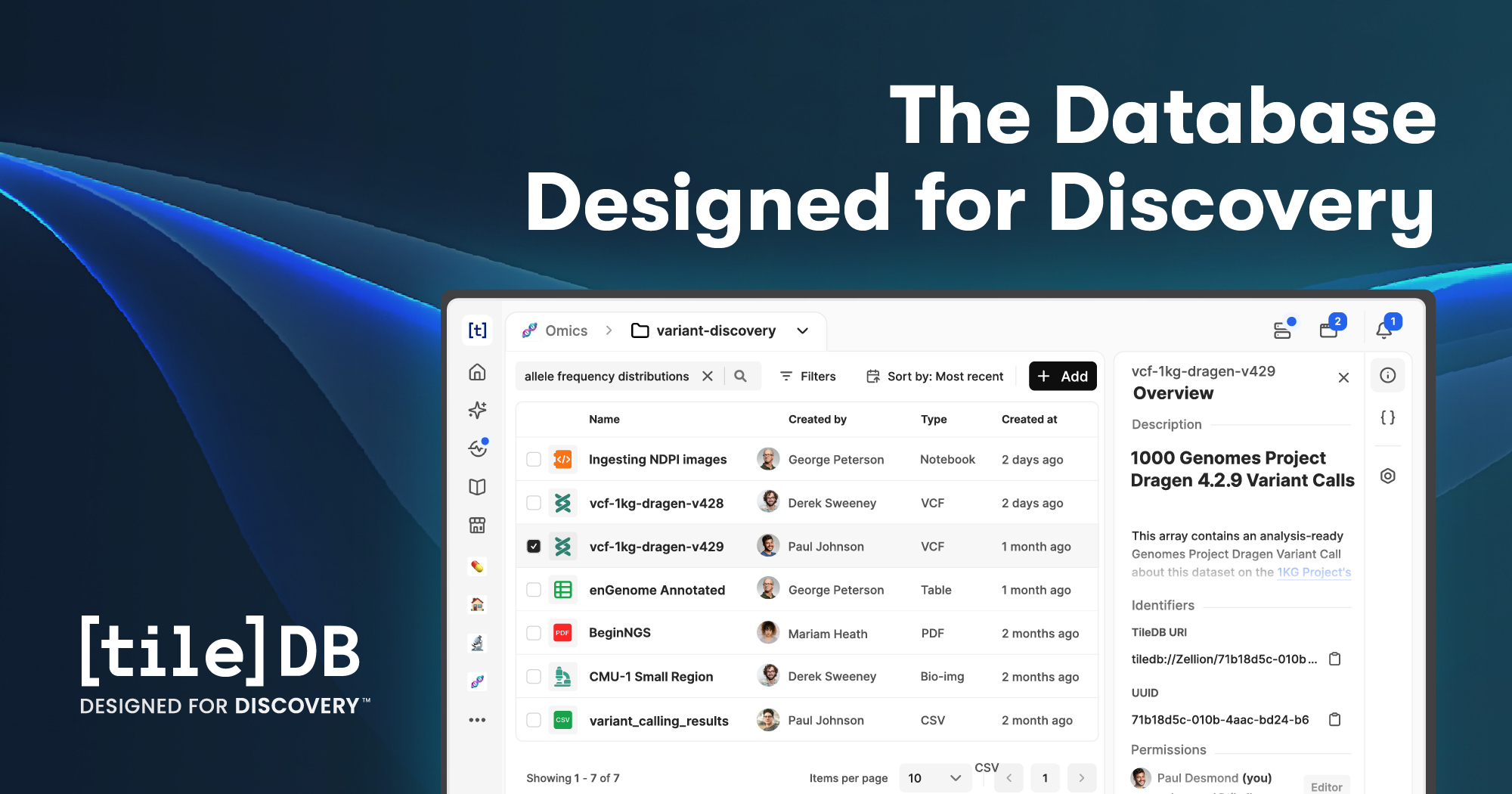
TileDB Inc. provides a universal “database for complex data” built around a multi-dimensional array engine that can store and manage tables, dataframes, genomics, Earth observation, point clouds, video, and other large-scale data in a single system.
[in63xy]
TileDB focuses on enabling data scientists and enterprises to analyze diverse data directly in object stores like S3, GCS, and Azure Blob while using familiar tools and languages.
[in63xy]
Core platform features include a unified array-based storage engine (TileDB Embedded) and a cloud service (TileDB Cloud) for scalable compute, access control, and collaboration over array datasets.
[in63xy]
The system offers native integrations with ecosystems such as Python, R, Spark, and SQL engines, providing high-performance access patterns for both dense and sparse data.
[in63xy]
Key features (priority order):
- Multi-dimensional array engine for dense and sparse arrays, described as “a powerful engine for storing and accessing dense and sparse multi-dimensional arrays.” [in63xy]
- Support for complex data types and modalities (tables, genomics, Earth observation, point clouds, video) under a unified storage model. [in63xy]
- TileDB Cloud service for “secure sharing, computing, and governance” on TileDB-managed arrays in the cloud. [in63xy]
- Integration with major languages and tools (e.g., Python and R packages advertised in package registries like CRAN/Bioconductor). [q593wx]
- High-performance access patterns designed for large-scale scientific and analytical workloads in HPC and research clusters. [in63xy]
Screenshots
No reliable source found.
Product Roadmap / Announcements
As of May 23, 2026,
- No reliable source found for public roadmap or announcements in the last 6 months.
Recent Developments
- No reliable source found for news or developments in the past 90 days focused specifically on TileDB Inc. or its products.
History and Origin Story
TileDB is described in software catalogs and research/HPC documentation as a “modern database engine for complex data based on multi-dimensional arrays,” indicating origins in serving scientific and analytic workloads that require dense and sparse array storage at scale.
[in63xy]
Its positioning in national research infrastructures and HPC ecosystems (e.g., Alliance Canada software stack) suggests it emerged as infrastructure to support data-intensive science before broadening into a commercial universal database platform.
[in63xy]
Fundraising History
No reliable source found for specific equity funding rounds or investors.
| Round | Date | Amount | Lead investor |
| Total | – | – | – |
Investors:
- No reliable source found.
Notable Team Members
No reliable source found for named founders or current executives that can be tied directly and unambiguously to TileDB Inc. at tiledb.com using the provided search set.
Market Sizing
Category, Market Size, and Category Growth
TileDB fits into the categories of “Databases,” “Database-Wrappers,” and “Data-Utilities,” as indicated by its metadata and catalog listings describing it as a database engine for complex data.
[in63xy]
Broader market sizing for multi-model or analytical databases, data platforms, and array databases is not directly quantified in the sources reviewed, and no credible analyst estimates specific to TileDB’s exact segment are present in the current search results.
Pricing
| Tier | Price | Notes |
| – | – | No public pricing found in the available sources. |
Revenue Trajectory Estimates
No reliable source found for revenue or ARR estimates.
Competitive Landscape
Who it’s for, who it’s not for
TileDB is suited for data scientists, researchers, and enterprises working with large-scale, dense or sparse multi-dimensional data—such as genomics, satellite imagery, and other complex analytical datasets—who need high-performance access and flexible cloud deployment.
[in63xy]
It also fits HPC and research institutions that deploy shared storage engines across clusters, as reflected by its inclusion in national research software stacks.
[in63xy]
TileDB is not an ideal fit for teams whose needs are limited to simple transactional workloads, traditional row-oriented OLTP databases, or small-scale datasets that do not benefit from an array-native model.
[in63xy]
It is also less suitable for organizations that require fully managed pricing-transparent SaaS databases with straightforward web UI-centric workflows and minimal infrastructure understanding, since its strongest use cases emphasize integration into technical data and HPC environments.
[in63xy]
Viable Alternatives
- SciDB – Array database focused on scientific data and multi-dimensional analytics, conceptually similar for dense/sparse arrays.
- ClickHouse – Columnar analytical database for large-scale analytics on tabular data; an alternative for many analytics workloads though not array-native.
- PostgreSQL + extensions – General-purpose relational database that, with extensions, can handle some complex data but not with native array-engine focus.
- Apache Parquet + query engines – File format plus engines like Spark/Trino for large analytical datasets, offering an alternative storage+compute stack.
Competitor Table
| Competitor | Description |
| SciDB | Array database system for large-scale scientific and analytic workloads using multi-dimensional arrays. |
| ClickHouse | Open-source columnar analytical database optimized for high-performance OLAP queries on large datasets. |
| PostgreSQL | Open-source relational database that can store arrays and complex types but is primarily row/relational rather than array-native. |
| Apache Parquet | Columnar storage format used with engines like Spark and Trino as an alternative for large analytical data storage and query. |