





Inference In AI
Defining and Describing Inference in AI
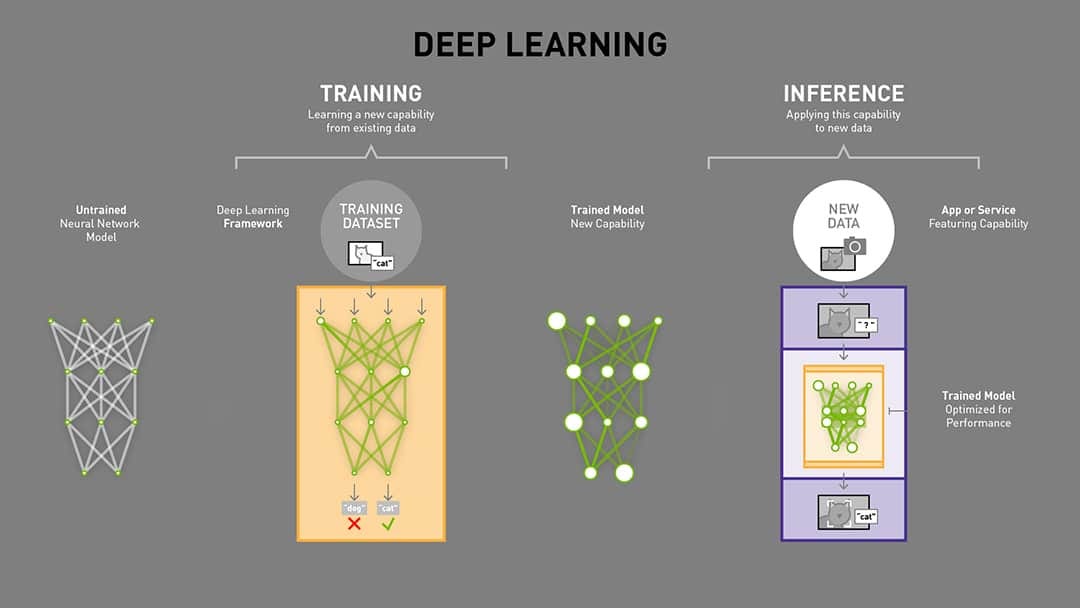
Inference in AI is the use of a trained model to generate outputs (predictions, decisions, or content) on new data, which is the part of AI that users, customers, and business processes actually experience in production.
[zbu0rv]
[zc64ed]
[6mhuni]
[2cuxzt]
For innovation work, inference is the deployment and usage phase of AI—where a model that has already been trained is run inside a product, workflow, or business system to answer queries, classify items, detect fraud, recommend content, or generate text and images.
[zbu0rv]
[zc64ed]
[6mhuni]
[2cuxzt]
It applies whenever founders or enterprises talk about “serving LLM calls,” “latency,” “tokens per second,” “cost per query,” “on-device vs cloud,” or “GPU spend” for an AI feature.
[zbu0rv]
[zc64ed]
[6mhuni]
[pwf01n]
It does not cover how the model learns its parameters (training) or how teams design prompts, governance, or UX around those calls, though those deeply shape inference economics and quality.
[yn8ztb]
[6mhuni]
[qw37ve]
An innovation consultant cares about inference because it directly drives unit economics, scalability, infra choices, pricing models, and customer experience for AI-native and AI-enabled products.
[zbu0rv]
[zc64ed]
[6mhuni]
[pwf01n]
Disambiguation
Primary sense — the innovation-consulting sense
Inference in AI (deployment sense): the process of running a trained AI model on new, unseen inputs to produce outputs such as predictions, classifications, recommendations, or generated content in real-world applications.
[zbu0rv]
[zc64ed]
[6mhuni]
[2cuxzt]
Other senses
1. Logical / reasoning sense in AI research
Logical inference in AI: the process of deriving new conclusions from existing facts using formal logic, rules, or probabilistic reasoning systems, often in symbolic AI or knowledge-based systems.
[m3guxz]
- In classical AI, inference referred to rule-based reasoning—“drawing logical conclusions, predictions, or decisions based on available information, often using predefined rules, statistical models, or machine learning algorithms.” [m3guxz]
- This includes methods like forward chaining, backward chaining, and probabilistic reasoning over knowledge graphs or expert systems, which are still relevant in domains like configuration, diagnostics, and certain planning systems. [m3guxz]
- For innovation consulting, this sense matters when evaluating startups that build symbolic reasoning engines, knowledge graphs, or hybrid neuro‑symbolic systems, where “inference” may mean logical rule execution rather than neural network forward passes. [m3guxz]
Etymology and Origin
- The term “inference” originates in formal logic and statistics as the act of deriving conclusions from premises or data; it entered AI in early symbolic systems to describe automated reasoning from rules and facts. [m3guxz]
- As machine learning and deep learning matured, the community drew a sharp distinction between “training” (learning model parameters from data) and “inference” (applying the trained model to new data), a distinction widely used in ML systems, cloud platforms, and hardware documentation. [yn8ztb] [6mhuni] [qw37ve]
- Modern enterprise and startup usage—“AI inference at scale,” “LLM inference cost,” “edge inference”—was popularized as cloud providers, accelerator vendors, and AI infra startups began marketing specialized hardware and platforms optimized for running models in production rather than training them. [zbu0rv] [zc64ed] [6mhuni] [2cuxzt] [pwf01n]
Adjacent Vocabulary
- Synonyms
- Antonyms
- Data collection / Data Labeling: Upstream phases that capture and annotate data, before any model learns or infers; often contrasted with inference in ML pipelines. [yn8ztb] [qw37ve]
- Adjacent terms
Usage in Practice
- A Google tech lead explains: “Inference in general is the way we actually use the model to do something useful… First, we have to train the model… So inference is what allows us to actually take all that and use it.” [j3cwhq]
- SUSE, discussing enterprise deployments, writes: “AI inference is the operational phase where trained machine learning models make real-time predictions on new data in production environments.” [pwf01n]
- SambaNova, an AI systems company, notes: “AI inference is the process of using a trained AI model to analyze new, unseen data and generate outputs such as predictions, classifications, or generated content.” [2cuxzt]
- A Google Cloud explainer aimed at product teams states: “AI inference is the process of running a trained AI model to make predictions on new, unseen data.” [6mhuni]
Common Misuses
- Labeling prompt engineering or orchestration as “inference optimization” when the underlying concern is UX or workflow design rather than the performance characteristics of the model execution; better terms include prompt design, agent orchestration, or pipeline optimization. [j3cwhq] [yn8ztb] [6mhuni]
- Marketing “zero‑inference cost” for products that merely hide costs in a fixed SaaS price, which confuses buyers about infra economics; better to talk about bundled inference costs or all‑inclusive pricing rather than implying inference is free (it always consumes compute resources). [zbu0rv] [zc64ed] [pwf01n]