





ai-toolkit/data-augmenters/serpapi
Value Proposition & Features
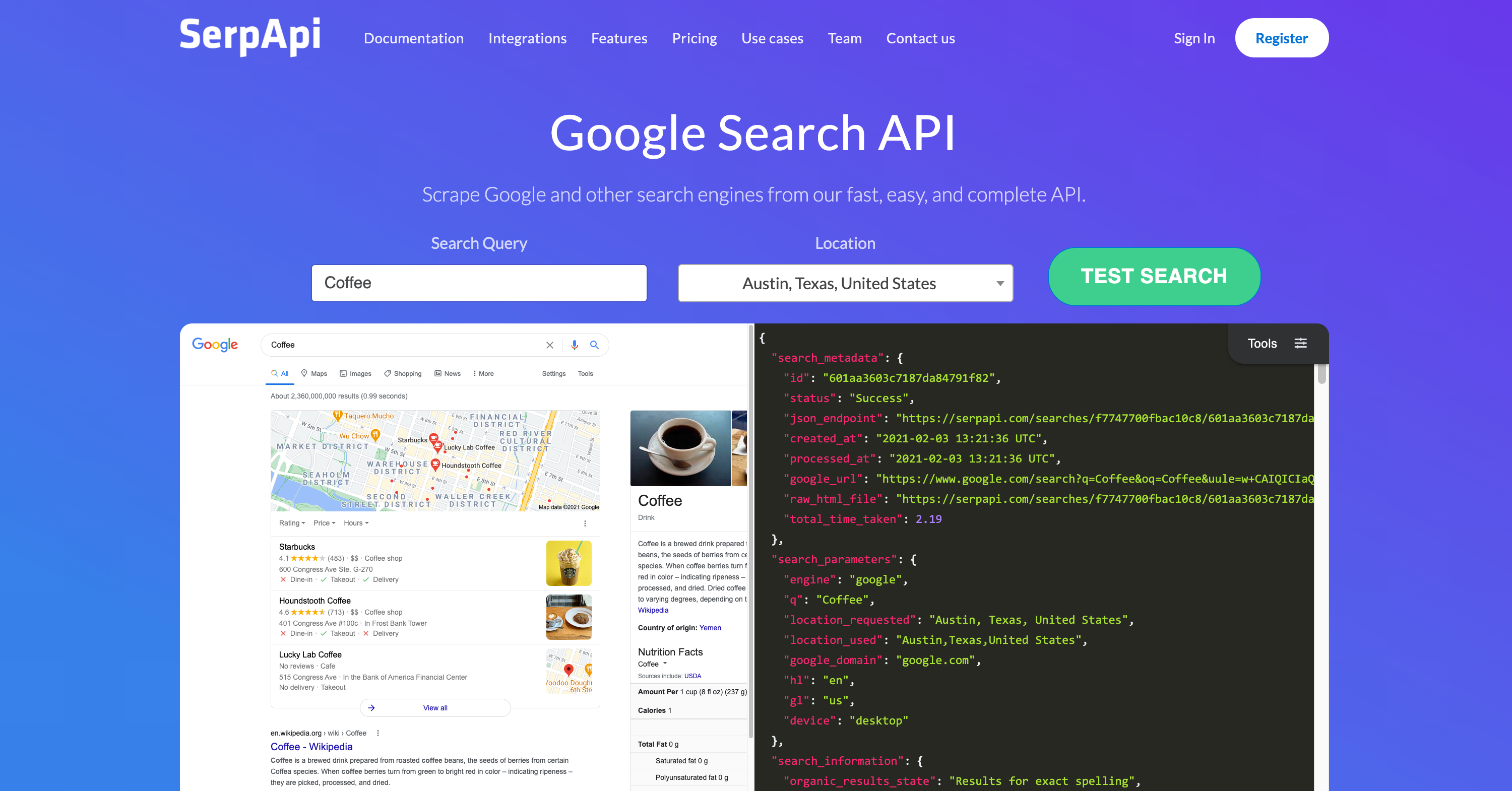
SerpAPI is a real-time API to access Google search results, and its own description says it handles proxies, captchas, and parsing of rich structured data.[1] Its positioning is developer tooling for programmatic search-result extraction rather than a consumer search product.[1]
- Google Search result extraction: SerpAPI’s tutorial content centers on scraping Google-derived search data with API parameters such as
numandnext_page_tokenfor pagination.[1] - Captcha and proxy handling: The product description explicitly says SerpAPI handles proxies and solves captchas on behalf of users.[1]
- Structured data parsing: SerpAPI says it parses “all rich structured data” from search results.[1]
- Pagination support: Documentation in the tutorial explains sequential retrieval of result pages via
next_page_token.[1] - Ads Transparency / competitor research use case: SerpAPI’s blog frames one use case as scraping competitors’ Google Ads data using Python and Google Ads Transparency Center data.[1]
Competitive Landscape
Who it's for, who it's not for
SerpAPI appears aimed at developers and data teams that need programmatic access to Google search results, ads data, and structured search metadata.[1] It is not positioned for casual end users who want a consumer search experience, and the provided results do not indicate a fit for unrelated use cases outside search-result extraction.[1]
Viable Alternatives
- Logposervices — Presents itself as a SerpAPI alternative for SERP, Google Maps, and News, but the provided result is marketing-oriented and offers limited technical detail.[2]
- Direct scraping with Python — A lower-level substitute when teams want to implement their own parsing and pagination logic instead of using a managed API; SerpAPI’s own tutorial shows the kind of workflow such an alternative would need to reproduce.[1]
Competitor Table
| Competitor | Brief description |
| Logposervices | Marketed as a SerpAPI alternative for SERP, Google Maps, and News retrieval.[2] |
| Direct scraping | DIY approach that replaces a managed API with custom scraping, parsing, and pagination logic.[1] |