





Mean Time to Recovery
(2025-09-17T19:50.983Z)
Perplexity Query
(2025-09-17T19:50
.983Z)
Question:
Write a comprehensive one-page article about "Mean Time to Recovery".
Model: sonar-pro
Mean Time to Recovery: A Critical Metric for System Reliability
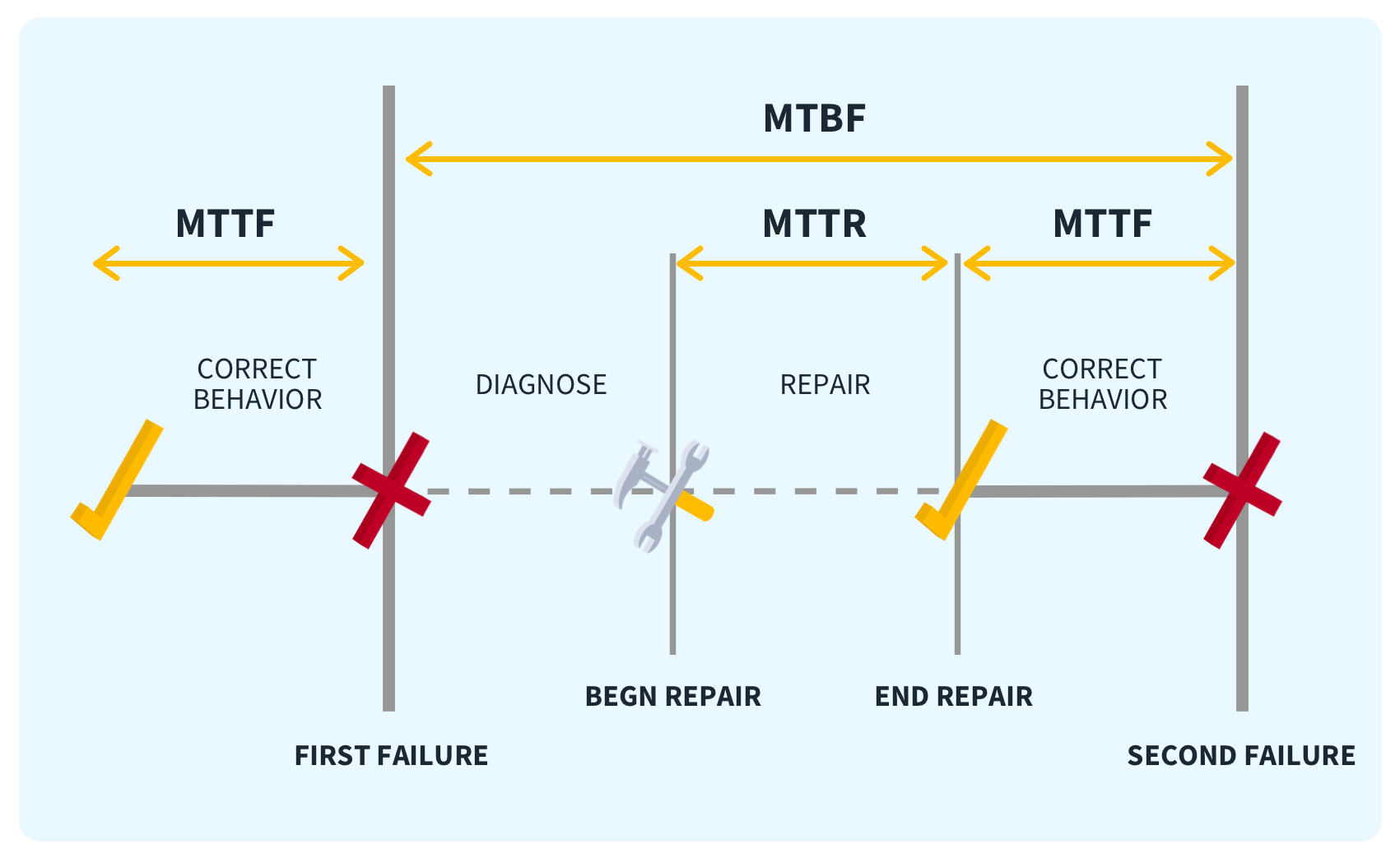
Mean Time to Recovery (MTTR) is a fundamental metric in IT operations, maintenance, and DevOps that represents the average time taken to restore a system to normal operations after an incident or outage.
[n17web]
[gsspo6]
[u0vyrk]
This value is significant because it quantifies an organization’s ability to quickly resolve disruptions—directly impacting service reliability, customer satisfaction, and operational costs.
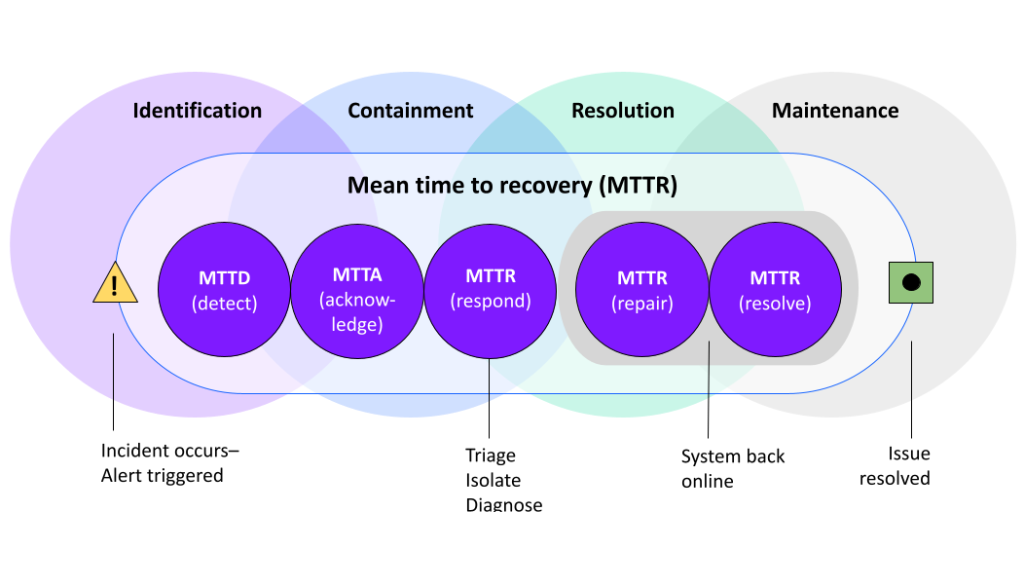
Understanding Mean Time to Recovery
At its core, MTTR measures how efficiently a team can detect, diagnose, and remediate system failures, from the moment an incident is reported to the point at which normal service is restored.
[n17web]
[79x869]
It is typically calculated with a straightforward formula:
latex
\[\text{MTTR} = \frac{\text{Total Downtime}}{\text{Number of Incidents}}
\]For example, if a cloud service experiences three incidents in a month, totaling six hours of downtime, the MTTR would be two hours per incident.
[n17web]
[gsspo6]
This quantifiable approach allows organizations to benchmark their incident response performance and establish realistic expectations with stakeholders.
Practical Examples and Use Cases
MTTR is widely applied across industries:
- In a financial institution, if a critical banking application goes offline, MTTR measures the average time it takes for IT teams to diagnose and resolve the outage, directly affecting customer trust and business continuity.
- SaaS providers use MTTR to evaluate and continually improve their incident response workflows, ensuring software downtime is minimized and user experience remains seamless.
- Manufacturing environments rely on MTTR for machinery repairs—shorter MTTR means less production loss and improved plant efficiency. [n17web]
Benefits and Applications
A low MTTR is a strong indicator of system resilience and operational maturity.
[n17web]
[79x869]
Organizations benefit by:
- Reducing lost revenue associated with downtime.
- Improving customer satisfaction through reliable service availability.
- Enhancing transparency by setting and communicating clear recovery expectations.
- Meeting regulatory or contractual SLAs (Service Level Agreements) for uptime and availability. [n17web]
Application areas extend to cybersecurity (rapid malware remediation), telecoms (quick network outage recovery), and enterprise IT (restoring business-critical services).
[u0vyrk]
Challenges and Considerations
While optimizing MTTR is desirable, challenges exist:
- Complex systems—such as those built on microservices or hybrid cloud architectures—can complicate diagnosis, extending recovery times. [79x869]
- Focusing solely on MTTR may cause teams to prioritize speed over thorough root cause analysis, potentially neglecting underlying issues and increasing future risk. [u0vyrk]
- Incident severity and context must always be considered; a low MTTR for minor glitches is less important than rapid recovery from critical, high-impact failures. [n17web]
Current State and Trends
MTTR has become a central metric in digital operations, embraced by DevOps, SRE (Site Reliability Engineering), and ITSM (IT Service Management) teams globally.
[gsspo6]
[79x869]
Vendors like PagerDuty, LaunchDarkly, and ServiceNow offer integrated tools and dashboards for real-time tracking and benchmarking of MTTR within incident management platforms.
[gsspo6]
[79x869]
Recent trends highlight the use of automation, AI-driven root cause analysis, and proactive monitoring to both detect and recover from failures faster. Cloud-native architectures and feature management systems increasingly allow teams to rollback problematic deployments instantly, further driving down MTTR.
[79x869]

Future Outlook
Future developments in MTTR management are closely tied to AI and machine learning. These technologies promise even faster identification of incidents, autonomous remediation, and predictive maintenance—potentially transforming recovery from a manual, reactive process to an automated, strategic capability. This evolution will help organizations achieve near-zero downtime and deliver continuous, reliable digital experiences, raising customer expectations for availability across all sectors.
Conclusion
Mean Time to Recovery serves as a crucial barometer of how resilient and efficient an organization’s infrastructure truly is. As digital demands increase, mastering MTTR will remain essential for ensuring robust, trustworthy, and competitive services in the future.
[n17web]
[gsspo6]
[79x869]
[u0vyrk]
Citations
[n17web] 2025, Sep 16. Mean Time To Recovery (MTTR) - Jellyfish. Published: 2023-09-06 | Updated: 2025-09-16
[gsspo6] 2025, Sep 17. What is MTTR? - PagerDuty. Published: 2025-05-05 | Updated: 2025-09-17
[79x869] 2025, Sep 17. Mean Time to Restore (MTTR): What It Is & How to Reduce It. Published: 2024-09-11 | Updated: 2025-09-17
[u0vyrk] 2025, Jun 16. What is MTTR? MTTR Explained: A Key Metric for Success - Tanium. Published: 2024-09-27 | Updated: 2025-06-16
[5]: 2025, Sep 17. Explained: All Meanings of MTTR and Other Incident Metrics. Published: 2024-04-22 | Updated: 2025-09-17
[6]: 2025, Sep 16. What is Mean Time to Repair (MTTR)? - IBM. Published: 2023-04-27 | Updated: 2025-09-16
[7]: 2025, Sep 17. Mean Time to Recovery (MTTR) in DevOps: Why It Matters | Faros AI. Published: 2025-09-11 | Updated: 2025-09-17
[8]: 2025, Sep 17. What's MTTR? Mean Time to Repair: Definitions, Tips, & Challenges. Published: 2024-12-05 | Updated: 2025-09-17