Ingestion Agents
Defining and Describing Ingestion Agents
- Ingestion agents are specialized AI components that automate the extraction, structuring, and preparation of complex enterprise data for agentic workflows, enabling accurate retrieval and reasoning in RAG systems.
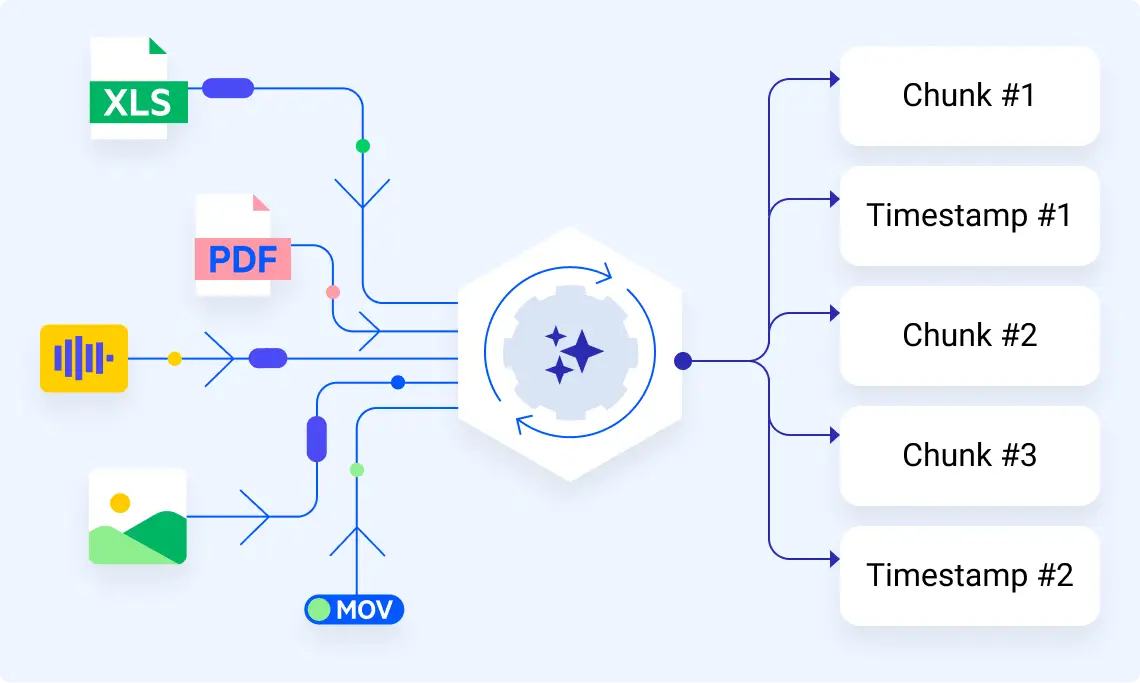
- Ingestion agents handle the initial phase of processing diverse data sources like PDFs, images, tables, audio, and scanned documents, converting them into structured, searchable formats suitable for AI analysis and storage in knowledge bases [1][2][3][5].
- They apply when building production-scale AI agents that must parse millions of enterprise files, such as insurance forms or financial statements, without manual intervention, preserving semantic meaning through chunking, metadata enrichment, and embeddings [1][5].
- This matters because it bridges messy real-world data to high-fidelity AI inputs, reducing errors in downstream tasks like retrieval-augmented generation (RAG) and enabling scalable enterprise automation [3][5].
Uses in Context
- In enterprise AI platforms, ingestion agents power "high-accuracy document ingestion and retrieval across millions of enterprise files such as scanned insurance forms, data room files, and financial statements" [1].
- For generative AI agents, they perform "data ingestion... [that] extracts data from data source documents, converts it into a structured format suitable for analysis, and then stores it in a knowledge base" [2].
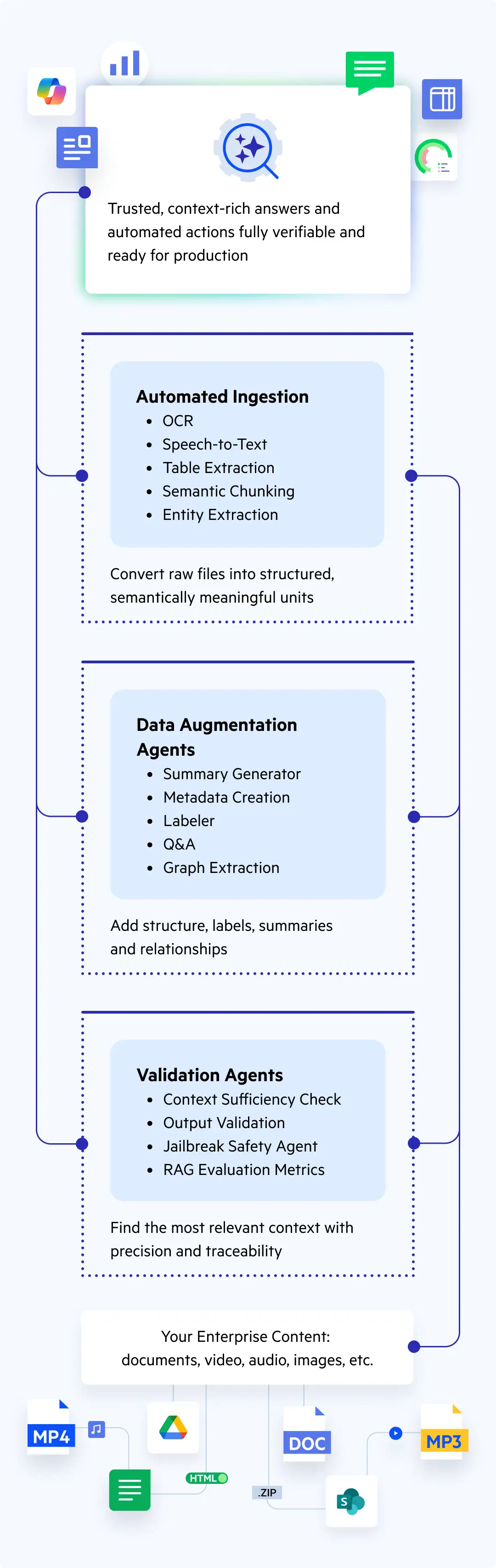
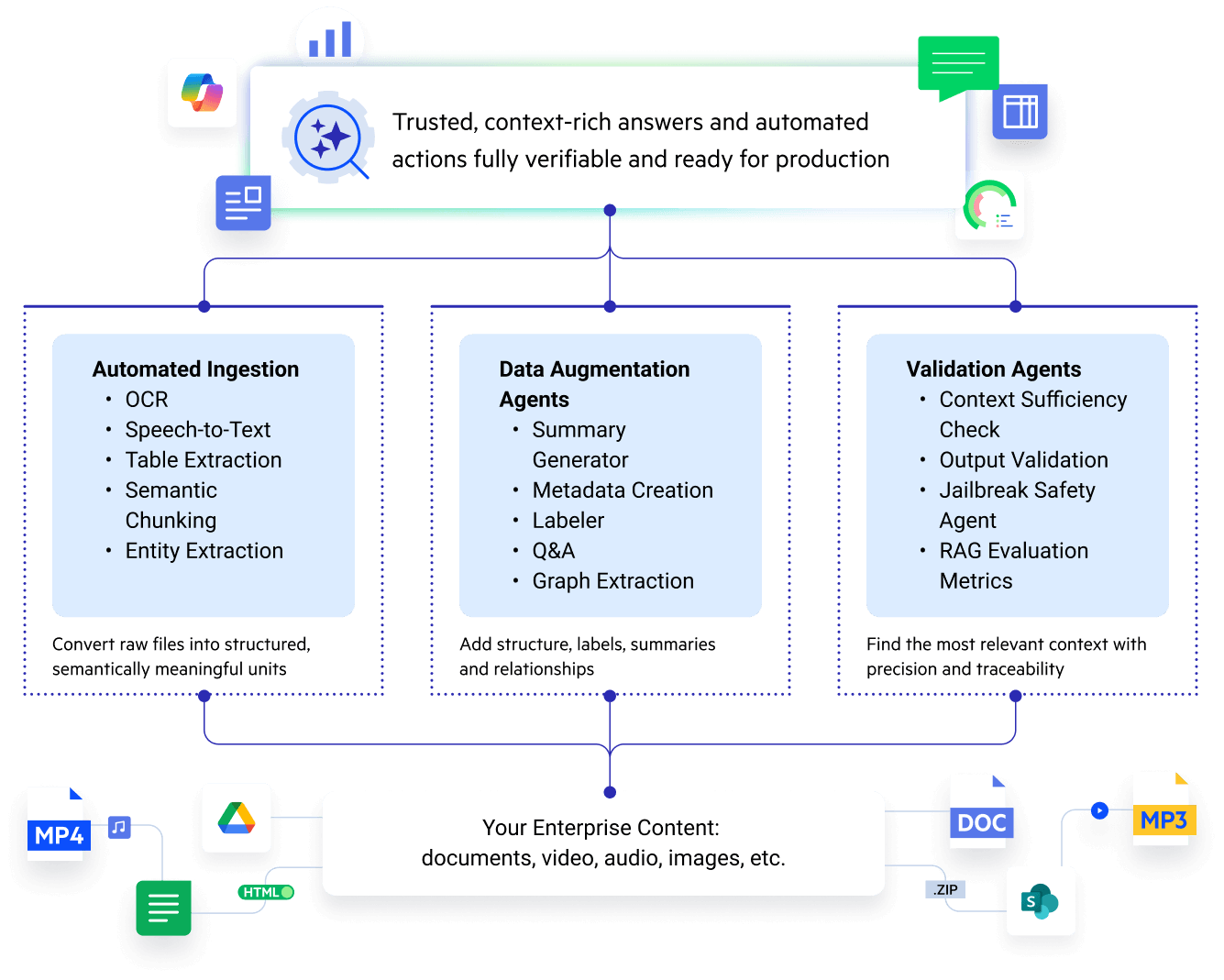
- In Agentic RAG solutions, "AI agents... handle ingestion, retrieval, reasoning and multi-step workflows," with "Data Augmentation Agents that transform messy enterprise content (PDFs, video, audio, tables, images, etc.) into structured, searchable and high-fidelity data" [3].
- In .NET AI development, ingestion agents support "collecting, reading, and preparing data from different sources... representing documents in a way that preserves their structure and meaning, splitting them into manageable chunks, and enriching them with metadata or embeddings" via pipelines like
IngestionPipeline<T>[5]. - They enable "robust, flexible, and intelligent data ingestion pipelines tailored for... Retrieval-Augmented Generation (RAG) scenarios," using unified
IngestionDocumentrepresentations that are "Markdown-centric because large language models work best with Markdown formatting" [5].
History of Use
Origins
- The concept emerges in 2024 enterprise AI contexts, with early practical articulation by StackAI, a startup building agent platforms, in their video "Scaling Document Ingestion for AI Agents: Lessons from..." which details using LlamaParse for production document processing [1].
- No single academic paper or book is identified as the definitive origin; instead, it arises from indie/startup implementations addressing RAG limitations in handling unstructured enterprise data, as seen in Progress's Agentic RAG agents for "ingestion... classification, content extraction, summarization and metadata enrichment" [3].
Evolution
- 2024: StackAI popularizes ingestion agents for scaling enterprise document parsing with tools like LlamaParse, focusing on "high-accuracy" handling of scanned forms and financials in AI agent platforms [1].
- 2025: Progress refines the idea into embedded "AI agents built into Agentic Retrieval-Augmented Generation (RAG) Technology" that automate "data ingestion to validation," including media-to-text conversion and semantic chunking [3].
- 2025: Microsoft adopts and frames it in .NET libraries as "data ingestion... for AI and machine learning scenarios, especially RAG," with modular
IngestionPipeline<T>APIs chaining readers, processors, chunkers, and writers [5].
Best Real-World Examples
- uses LlamaParse-powered ingestion agents for millions of enterprise files like insurance forms [1].
- Progress Agentic RAG deploys Data Augmentation Agents to transform PDFs, video, audio, and tables into structured data [3].
- Oracle Generative AI Agents manage ingestion jobs that download, extract, and store data in knowledge bases for RAG tools [2].
- Microsoft.Extensions.DataIngestion provides .NET building blocks like
IngestionDocumentandIngestionPipeline<T>for RAG pipelines [5]. - enables high-accuracy parsing of complex documents in agent workflows [1].
Case Studies
Stack AI, a leading enterprise agent platform startup, tackled the challenge of AI agents failing on real-world documents by developing ingestion agents integrated with LlamaParse. In production deployments shared in their 2024 video, they processed millions of files including scanned insurance forms, data room documents, and financial statements, achieving "high-accuracy document ingestion and retrieval." This allowed agents to understand enterprise content at scale, bypassing traditional OCR limitations and enabling reliable RAG. The result transformed agent reliability, proving ingestion agents as a foundational layer for production AI [1].
Progress, focusing on enterprise automation, embedded ingestion agents into their Agentic RAG solution to handle "messy enterprise content" across formats like PDFs, video, audio, tables, and images. Their Data Augmentation Agents automatically extract text, detect entities, transcribe media, and create semantic chunks, while Q&A/Summarization Agents generate metadata and interactive knowledge assets without SMEs. Launched around 2025, this freed users from manual tasks, delivering "accurate, explainable and aligned" responses with built-in evaluation via REMi (RAG Evaluation Metrics). It demonstrated how ingestion agents enable continuous QA loops, reducing risks in regulated workflows and outpacing generic RAG [3].
Microsoft popularized ingestion agents for developers via the
Microsoft.Extensions.DataIngestion package in 2025 .NET AI tools, addressing RAG needs beyond simple format conversion. The library's IngestionDocument unifies file types (PDFs, images, Word) into Markdown-centric structures, with IngestionPipeline<T> chaining readers from cloud/local sources, processors for enrichment, chunkers for splitting, and writers for vector stores. Adopted widely for flexible pipelines, it showed incumbents following open patterns to make "data usable for intelligent applications," preserving structure for LLM retrieval [5].