





Benchmarks
AI Model Performance Benchmarks
- MMLU/MMLU-Pro: Measures performance on massive multitask language understanding across subjects (math, medicine, law, etc.).
- GPQA (Graduate-Level Physics QA): Evaluates advanced scientific reasoning.
- AIME: Assesses mathematical problem-solving, often used for math Olympiad-level questions.
- SWE-Bench: Quantifies proficiency in real-world software engineering tasks.
- Chatbot Arena (Elo Scores): Dynamically ranks models based on head-to-head user engagement and feedback.
| Benchmark | Area Tested | Recent Top Scores (2025) |
| MMLU-Pro | Language Understanding | DeepSeek R1: 90.8%, Grok 4: 87%, GPT-4.5: ~85% [nxzyo6] |
| GPQA | Reasoning (Physics) | Grok 4: 88%, DeepSeek R1: 81%, Gemini 2.5 Pro: 86.4% [nxzyo6] |
| AIME | Math Olympiad Level | Grok 4: 94%, DeepSeek R1: 93.3%, GPT-4.5: ~90% [nxzyo6] [0ueat7] |
| SWE-Bench | Coding/Software Eng. | Grok 4: 72–75%, Gemini 2.5 Pro: 63.8%, DeepSeek R1: 57.6% [nxzyo6] |
| LiveCodeBench | Live Coding | DeepSeek R1: 73.3%, Claude 4 Opus: ~74%, GPT-4.5: ~78% [nxzyo6] |
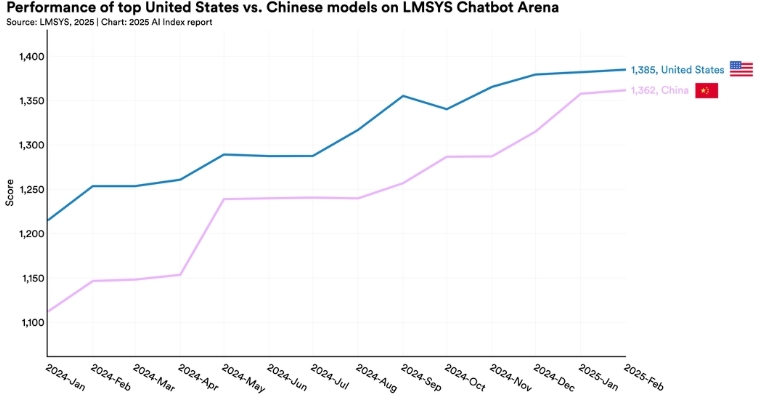
- On benchmarks like MMMU, GPQA, and SWE-Bench, scores rose by 18–67 percentage points within a year. [s3j99t]
- Inference costs for GPT-3.5–level performance dropped more than 280-fold; hardware costs and energy use decreased by 30–40% per year. [s3j99t]
- Model scale (number of parameters and training compute) continues to double every few months, yet the performance gap between top models has shrunk from 12% to just 0.7%, making the frontier highly competitive. [s3j99t]
- Models now outperform humans in some programming and reasoning tasks with time constraints, and open models have nearly rivaled closed models on certain benchmarks. [s3j99t]

- Current state-of-the-art models such as DeepSeek R1, Grok 4, GPT-4.5, Gemini 2.5 Pro, and Claude 4 Opus consistently achieve scores above 85%—and in some cases above 90%—on historically challenging tasks, reflecting dramatic advances in reasoning, coding, multilinguality, and robustness even compared to GPT-4. [nxzyo6] [sab6tu] [i48jo2] [0ueat7]

Citations
[nxzyo6] 2025, Sep 10. AI by AI: Top 5 Large Language Models (July 2025). Published: 2025-07-11 | Updated: 2025-09-10
[s3j99t] 2025, Nov 21. The 2025 AI Index Report | Stanford HAI. Published: 2024-09-10 | Updated: 2025-11-21
[sab6tu] 2025, Nov 20. Top 9 Large Language Models as of November 2025 | Shakudo. Published: 2025-10-05 | Updated: 2025-11-20
[8kt4xe] 2025, Nov 21. 25 AI benchmarks: examples of AI models evaluation - Evidently AI. Published: 2025-10-21 | Updated: 2025-11-21
[i48jo2] 2025, Nov 21. LLM Leaderboard 2025 - Vellum AI. Published: 2025-11-19 | Updated: 2025-11-21
[dtfaf1] 2025, Nov 21. Data on AI Benchmarking - Epoch AI. Published: 2024-11-27 | Updated: 2025-11-21
[0ueat7] 2025, Nov 21. 10 Best LLMs of November 2025: Performance, Pricing & Use Cases. Published: 2025-10-31 | Updated: 2025-11-21