Data Lakes
Defining and Describing Data Lakes
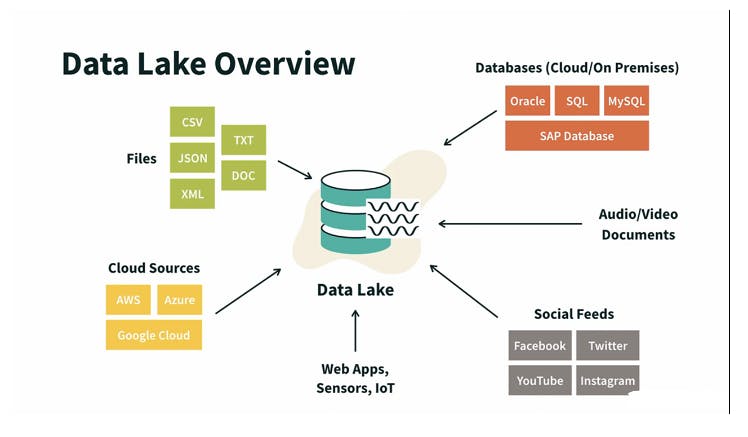
Uses in Context
- In enterprise data architecture, “data lake” refers to a central repository where an organization can keep “all of an organization's data in a single, central location,” saved “as is.” [t4timd]
- In architecture guidance, the term is used to emphasize governance problems as well as flexibility, since large raw repositories can become “swamps” without curation. [76qinj]
History of Use
Origins
- The modern definition of a data lake appears in contemporary cloud and data-platform documentation as a storage repository for raw, native-format data, with Microsoft explicitly framing it as a contrast to the data warehouse’s schema-on-write model. [d7we56]
Evolution
Best Real-World Examples
- Azure Data Lake Storage — Microsoft’s cloud storage platform is presented as a scalable data-lake implementation for raw, diverse data. [d7we56]
- Databricks Lakehouse — Databricks positions its platform around combining data-lake flexibility with warehouse-style management, showing how the term evolved in practice. [t4timd]
- Azure Data Lake Storage — Microsoft’s storage service is frequently used to store structured, semi-structured, and unstructured data at scale. [d7we56] [ur7j23]
- SAP Data Lake — SAP describes its offering as native-format storage for analytics and AI workloads. [qqz29h]
- Hadoop HDFS — Hadoop distributed storage is often cited as a distributed foundation for early data-lake deployments. [7wfhyv]
- Fivetran data lake catalogs — Catalog tooling illustrates the governance and metadata layer that mature data lakes need. [32z077]
Case Studies
A common enterprise pattern is to use a cloud object store as the raw landing zone for many data sources, then apply transformation only when a team needs a particular analysis.
[d7we56]
[7wfhyv]
Microsoft’s description captures this logic directly: a data lake keeps data in its “original, untransformed state,” with schema applied on read rather than on ingest.
[d7we56]
This case shows what the concept is for: preserving maximum optionality while avoiding premature modeling decisions.
[d7we56]
[7wfhyv]
Databricks’ materials reflect the next stage in the concept’s evolution, where the data lake is no longer just a repository but part of a broader analytics stack.
[t4timd]
Its framing of lakes as a way to keep data “as is” highlights why organizations adopted them for machine learning and cross-functional analytics, but the governance discussions around “swamps” show the operational risk of unmanaged growth.
[76qinj]
[t4timd]
[32z077]
This case shows that the value of a data lake depends not only on scale, but also on metadata, cataloging, and stewardship.
[76qinj]
[32z077]
SAP and similar enterprise vendors present data lakes as a foundation for analytics and AI that can accept structured, semi-structured, and unstructured inputs.
[qqz29h]
That framing indicates how the concept moved from a storage pattern into a platform strategy: the lake becomes the shared substrate for downstream data science, reporting, and operational analytics.
[qqz29h]
[ur7j23]
This case shows the concept’s broader role in modern data stacks, where raw storage is treated as an enabling layer rather than a final destination.
[qqz29h]
[ur7j23]